korpus, wstępna wersja pełna

Udostępniamy wstępną wersję pełnego korpusu. Ponieważ trwają prace weryfikacyjne (usuwane są drobne niezgodności zapisu, wykonywana jest dodatkowa korekta), może się on różnić od wersji ostatecznej, różnice te jednak nie będą wielkie.
Niniejsza wersja korpusu zawiera 1000 próbek, po 200 w każdym ze stylów. Cały korpus liczy 1 055 293 słów (segmentów między spacjami). Ponieważ kierowaliśmy się zasadą zapisywania pełnych zdań, długość próbki może się wahać nie więcej niż 10% od przyjętych 1000 słów, przy czym we fragmentach dramatu do liczby tej nie liczą się didaskalia i imiona postaci (z wyjątkiem pierwszego wystąpienia). Próbki krótsze niż 1000 słów stanowią 6,7% całości, w 9 wypadkach są to próbki krótsze, bez wyjątku należą one do krótkich wiadomości prasowych.
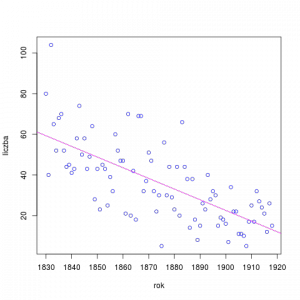
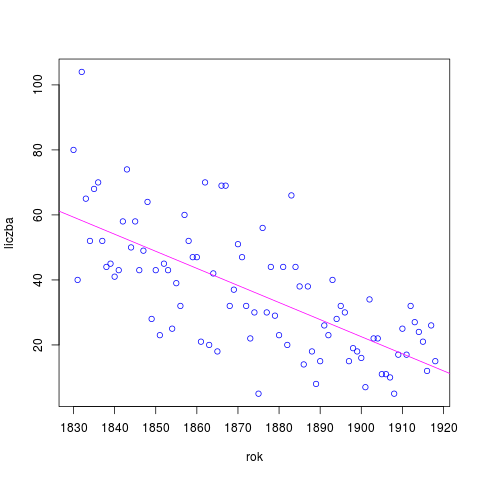
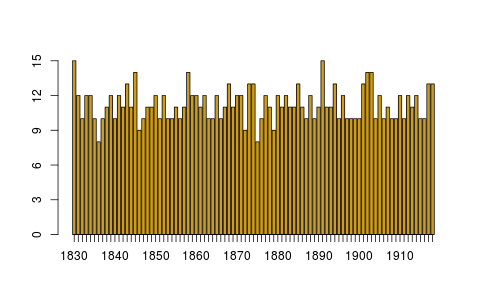
Na wykresach przedstawiamy liczbę próbek dla poszczególnych lat:
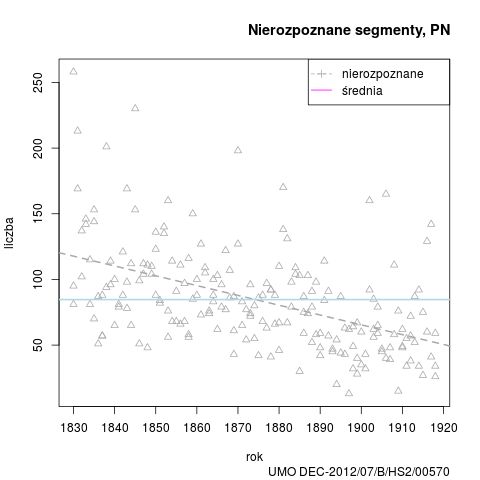
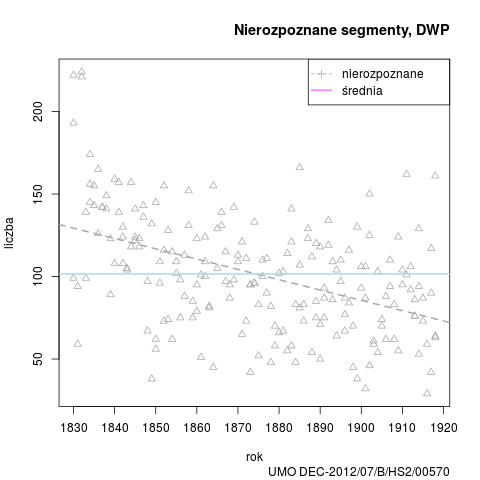
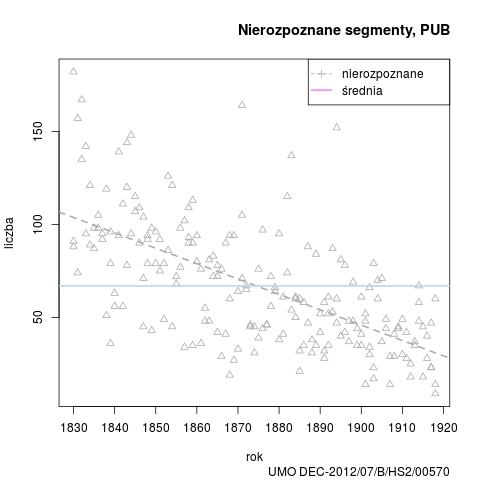
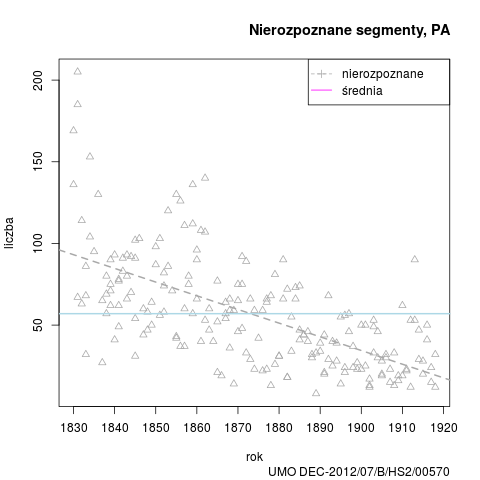
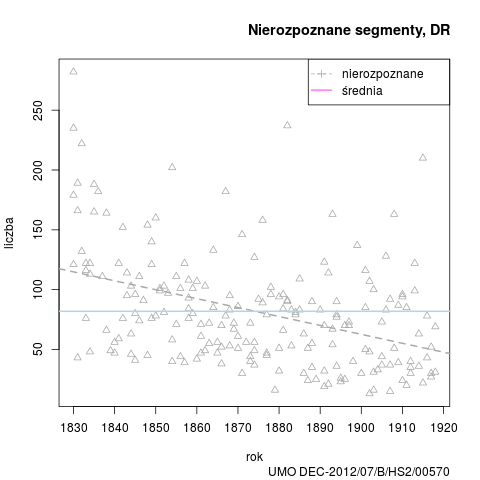
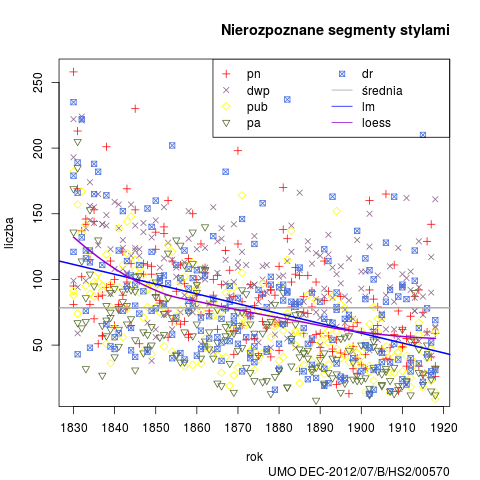
Podobnie jak w przypadku poprzednich wersji, przedstawiamy wykres nierozpoznanych segmentów w badanym okresie, oraz dane zbiorcze stylów:
Podział na style
Zastosowaliśmy podział na style zgodny ze Słownikiem frekwencyjnym polszczyzny współczesnej:
- popularnonaukowy
- drobne wiadomości prasowe
- publicystyka
- proza (artystyczna)
- dramat
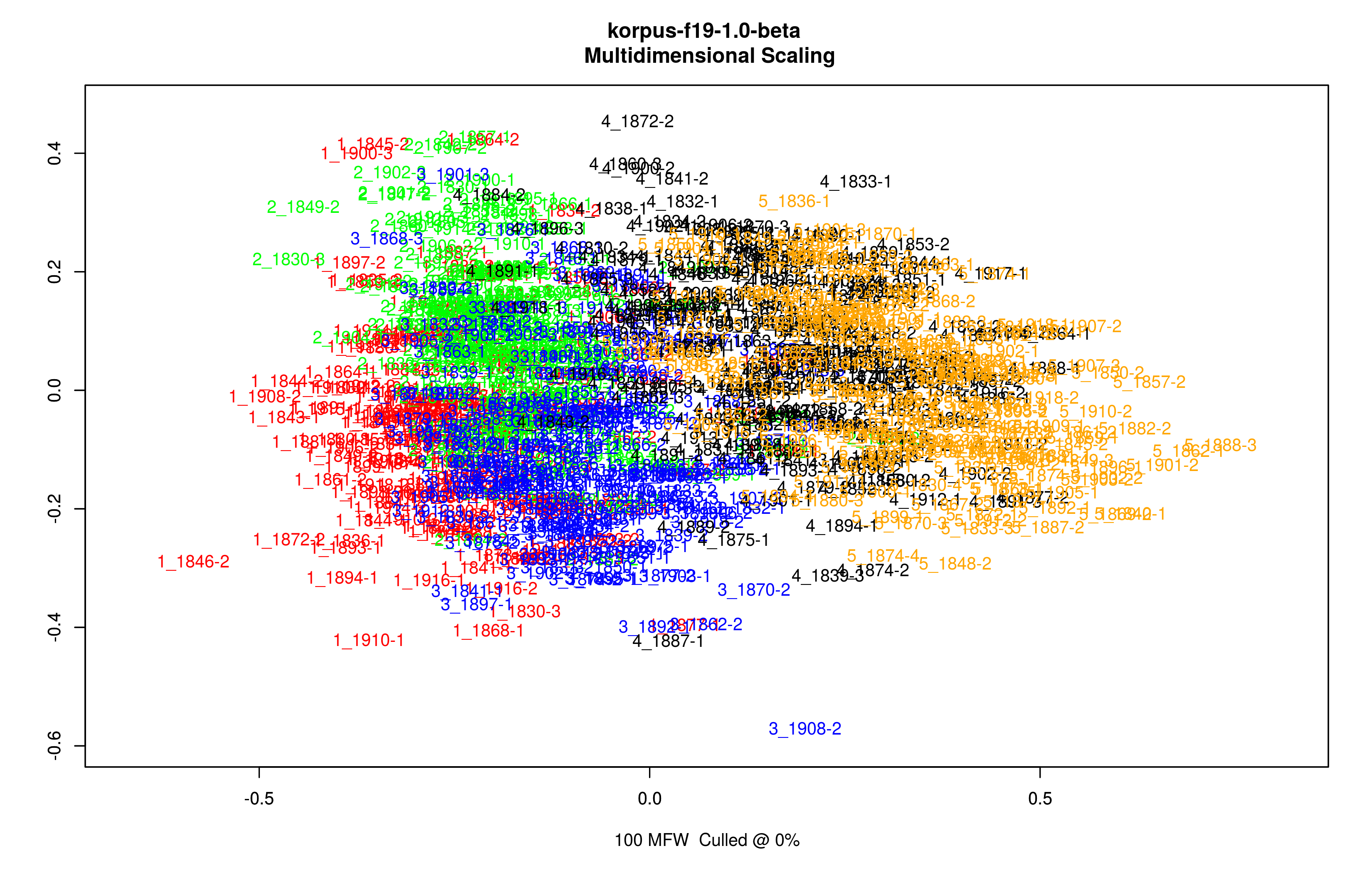
Style te się dobrze wyodrębniają, co pokazuje następujący wykres MDS:
Zróżnicowanie źródeł
Ze względu na ograniczoną liczbę dostępnych elektronicznie źródeł oraz cel korpusu (materiał językowy dla analizatora morfologicznego), staraliśmy się przede wszystkim zachować różnorodność źródeł (tekstów), a w następnej kolejności – autorów. Wydaje się jednak, że udało się stworzyć korpus o dość dużej różnorodności.
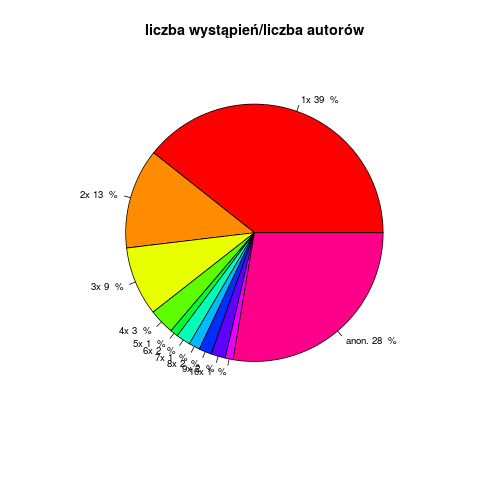
277 próbek to próbki anonimowe z różnych źródeł, pozostałe pochodzą z tekstów 506 autorów. W 392 przypadkach jest to jedyny tekst w próbce danego autora, w 63 – jeden z dwóch tekstów, w 29 – jedne z trzech, w 8 – jeden z czterech, 13 autorów wystąpiło więcej niż 5 razy, w każdym wypadku próbki pochodzą z różnych dzieł. Najczęściej występującym autorem jest Juliusz Słowacki (10 razy), następnie Eliza Orzeszkowa i Józef Ignacy Kraszewski. Jeśli przyjąć, że teksty z różnych źródeł pochodzą od różnych autorów anonimowych, w 60% wypadków autorstwo próbek się nie powtarza.
Jeśli chodzi o zróżnicowanie pozycji nieksiążkowych w publicystyce i drobnych wiadomościach prasowych, to próbki pochodzą ze 189 czasopism, w ok. 70% są to źródła wyzyskane jednokrotnie. Najczęściej cytowane są Gazeta Lwowska (17 razy) i Gazeta Warszawska (16 razy).
390 próbek pochodzi z dzieł wydanych w Warszawie, 156 – we Lwowie, 114 – w Krakowie, po ponad 50 – w Poznaniu, Wilnie i Paryżu.
Wykorzystane zasoby elektroniczne
W trakcie prac korzystaliśmy przede wszystkim z bibliotek cyfrowych, w pojedynczych wypadkach teksty zostały przepisane wprost z publikacji. Poniżej prezentujemy pełną listę zasobów, z których pochodzą teksty wykorzystane w próbkach:
- Polona (327)
- e-Biblioteka Uniwersytetu Warszawskiego (134)
- Wielkopolska Biblioteka Cyfrowa (100)
- Śląska Biblioteka Cyfrowa ( 80)
- Jagiellońska Biblioteka Cyfrowa (67)
- Google Books (65)
- WikiSource (55)
- Kujawsko-Pomorska Biblioteka Cyfrowa (20)
- PBI (16)
- Wojewódzka Biblioteka Publiczna im. Hieronima Łopacińskiego w Lublinie (14)
- Repozytorium Cyfrowe Instytutów Naukowych, Podkarpacka Biblioteka Cyfrowa, Radomska Biblioteka Cyfrowa (12)
- Podlaska Biblioteka Cyfrowa, Dolnośląska Biblioteka Cyfrowa (11)
- Biblioteka Cyfrowa Uniwersytetu Łódzkiego, Biblioteka Cyfrowa UMCS (8)
- Małopolska Biblioteka Cyfrowa (7)
- Pomorska Biblioteka Cyfrowa, Biblioteka Cyfrowa Politechniki Warszawskiej (6)
- Archive.org (5)
- Biblioteka Cyfrowa Uniwersytetu Warmińsko-Mazurskiego (4)
- Mazowiecka Biblioteka Cyfrowa, Chełmska Biblioteka Cyfrowa, Biblioteka Cyfrowa Regionalia Ziemi Łódzkiej, Biblioteka Cyfrowa Politechniki Lubelskiej, Biblioteka Cyfrowa Instytutu Nafty i Gazu – Państwowego Instytutu Badawczego, Akademicka Biblioteka Cyfrowa AGH (3)
- Świętokrzyska Biblioteka Cyfrowa, Biblioteka Literatury Polskiej w Internecie, BUW, Biblioteka Uniwersytetu Łódzkiego, Biblioteka Uniwersytetu Gdańskiego, Biblioteka im. Wacława Borowego (ILP UW), Biblioteka Cyfrowa UWM , Wolne Lektury (2)
- Zielonogórska Biblioteka Cyfrowa, Tarnowska Biblioteka Cyfrowa, Repozytorium Cyfrowe Instytutu Filozofii i Socjologii PAN, Płocka Biblioteka Cyfrowa, Łódzka Regionalna Biblioteka Cyfrowa, Kujawsko-Pomorska Biblioteka Cyfrowa, Krośnieńska Biblioteka Cyfrowa, Biblioteka Uniwersytecka w Toruniu, Biblioteka Kórnicka PAN, Biblioteka Główna Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie, Biblioteka Cyfrowa Uniwersytetu Wrocławskiego, Biblioteka Cyfrowa Uniwersytetu Ekonomicznego (1).
Zróżnicowanie autorskie
Zróżnicowanie autorów pokazuje syntetycznie wykres
Do pobrania
[wersja nieostateczna korpusu]
Podstawowe analizy
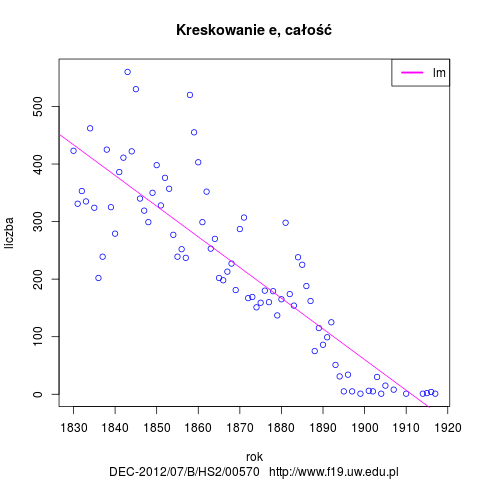
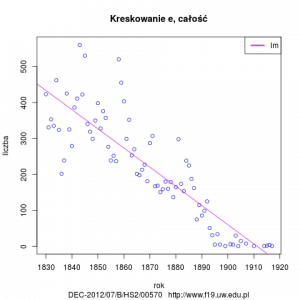
- Rozkład kreskowania e w badanym okresie.
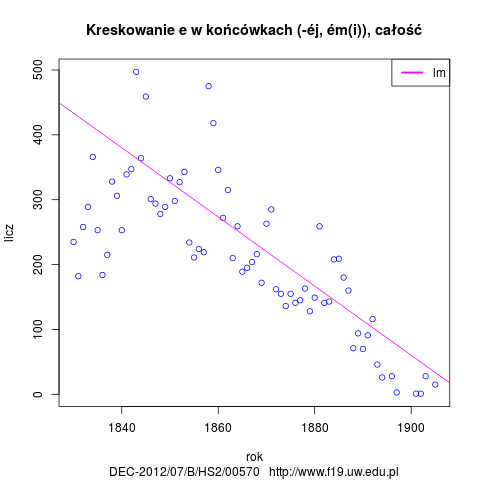
- Użycie é w końcówkach instr, loc sg masc, neut, instr pl, gen, dat, loc sg fem i adv comp.
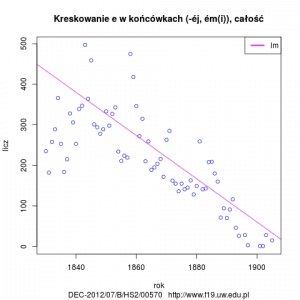
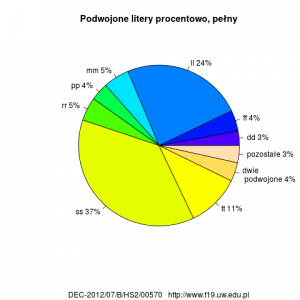
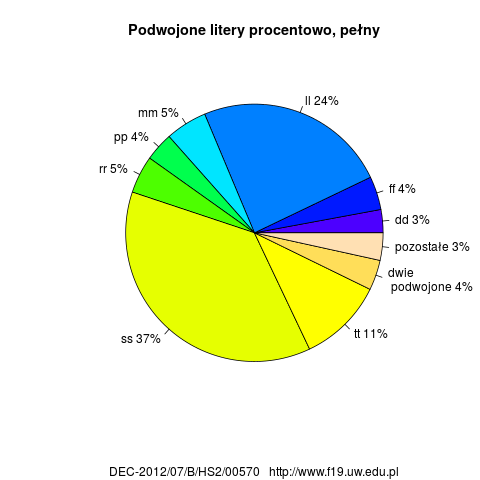
- Użycie podwojonych liter.