Korpus, wersja 0.2

Udostępniamy pierwszą wersję korpusu roboczego tekstów z lat 1830-1918. Jest to wersja, w skład której wchodzi 200 próbek podzielonych na pięć stylów funkcjonalnych. Obecny stan korpusu obrazuje 20% jego rozmiaru docelowego (docelowo ma składać się z 1000 próbek po 1000 słów).
W aktualnej wersji podział próbek w poszczególnych stylach przedstawia się następująco:
- teksty popularnonaukowe: 26
- drobne wiadomości prasowe: 30
- publicystyka: 36
- proza artystyczna: 83
- dramat: 29
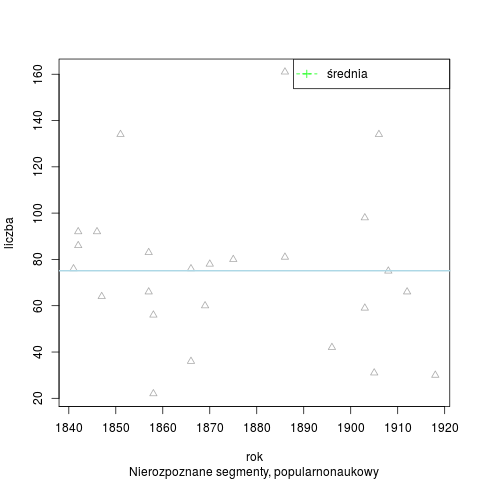
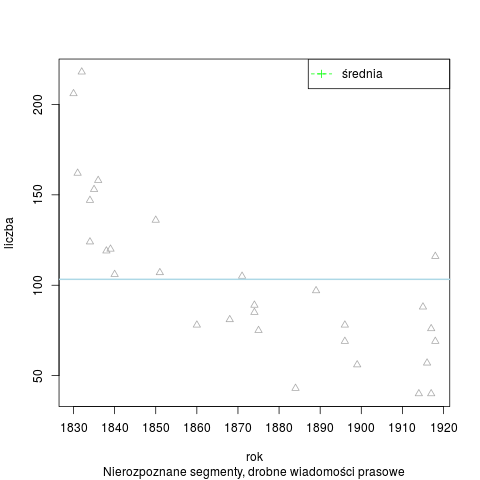
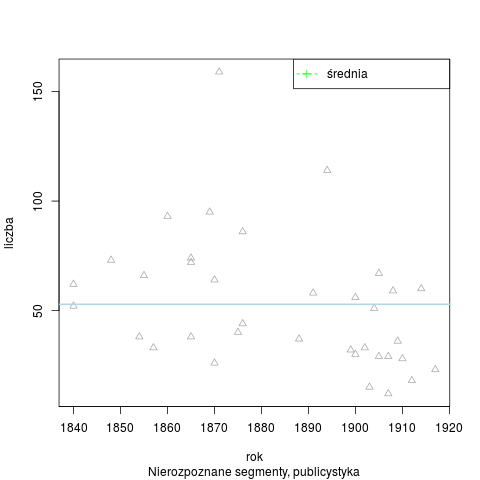
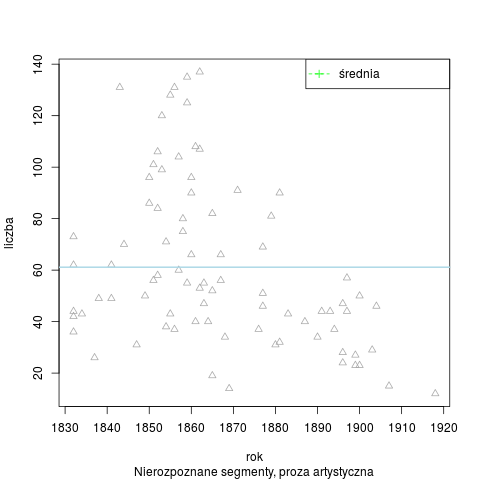
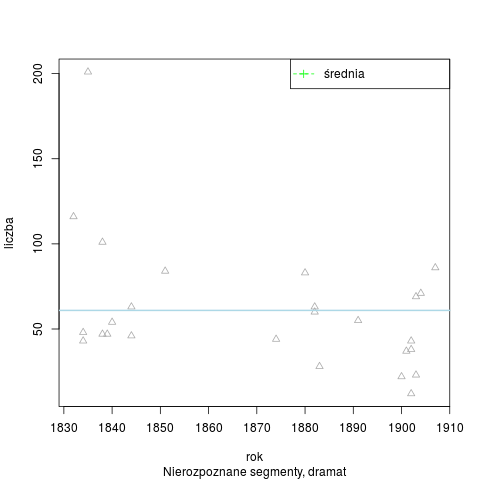
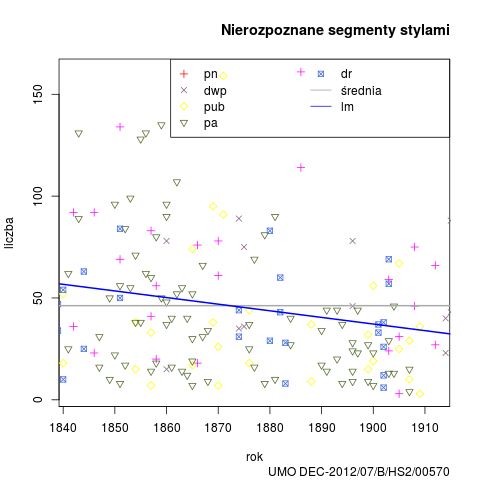
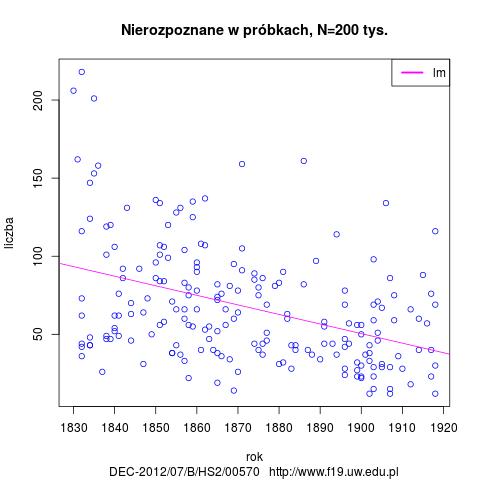
Łączna liczba słów tekstowych (od spacji do spacji) w korpusie wynosi 209 050 słów. Analizator Morfeusz SGJP (wersja danych z 13 kwietnia 2013 r.) rozpoznał w korpusie 444 180 segmentów, 15 119 słów tekstowych pozostało nierozpoznanych (wśród nich 8349 ciągów różnokształtnych). Rozkład segmentów nierozpoznanych w badanym okresie:
Do pobrania
Każda próbka składa się z dwóch części: pliku zawierającego tekst (pliki *_sample.txt) oraz metryczki (pliki *_meta.txt).
W korpusie przeprowadziliśmy obliczenia niektórych cech opisywanych przez Irenę Bajerową.
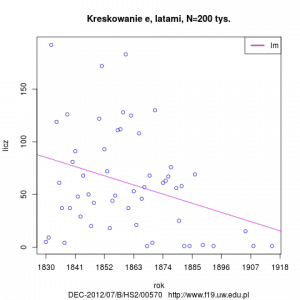
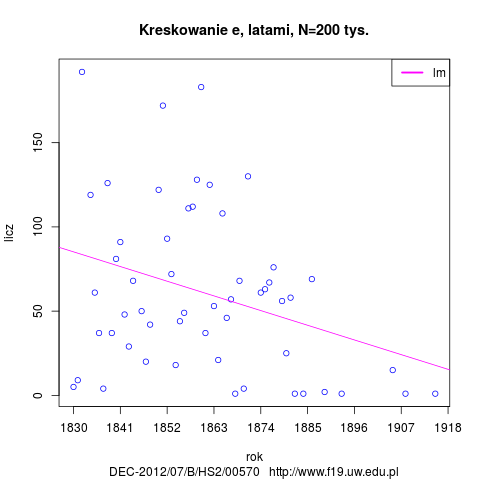
- kreskowanie e (é)
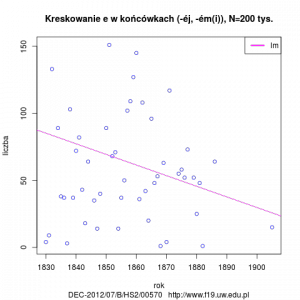
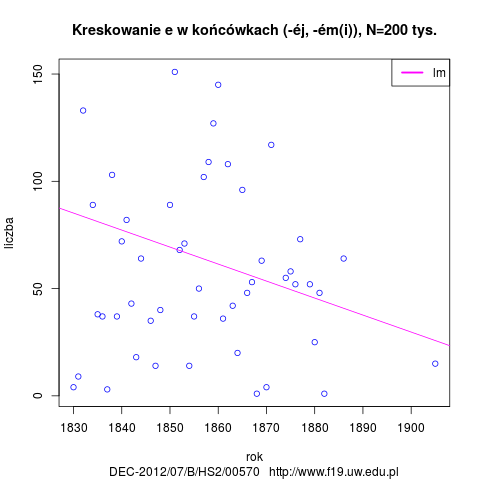
- użycie é w końcówkach instr. sg i loc pl masc, neut oraz gen, dat, loc fem (-ém, -émi, éj) oraz w formach adv comp
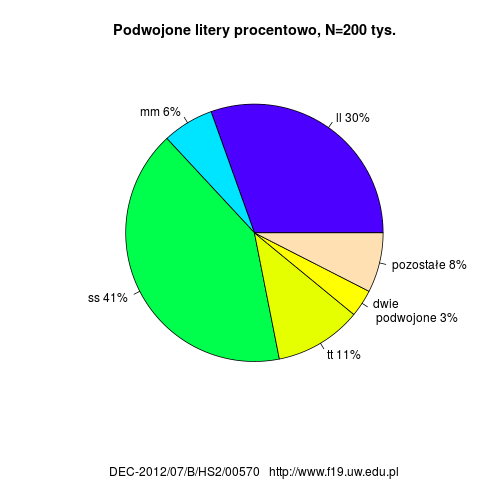
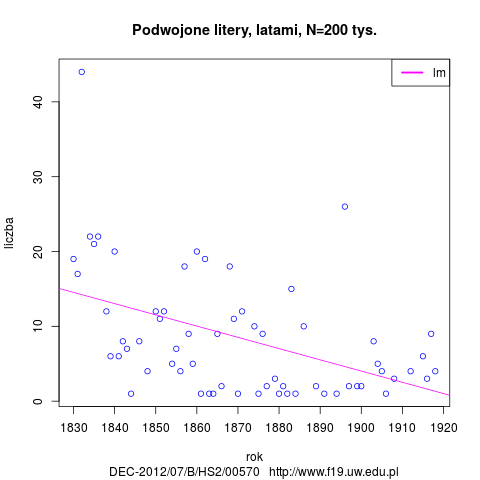
- stosowanie podwojonych liter zgodnie z pisownią oryginalną; uwaga! obliczenia uwzględniają też formy nazw własnych
[Dodane 2017]
Segmenty nierozpoznane wg stylów i łącznie w korpusie N=400 tys.